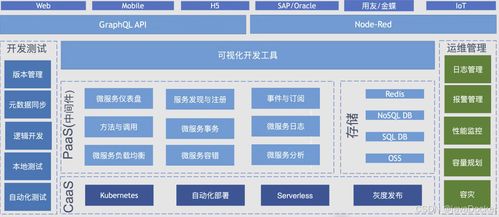
拆穿“超节点”伪装 无内存统一编址,本质仍是服务器堆叠
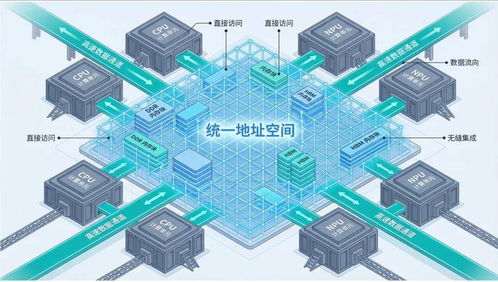
数据中心和云计算领域涌现出“超节点”(Hyper-Converged Node)等新概念,宣称通过软硬件深度集成,实现了前所未有的性能与效率飞跃。当我们深入技术内核,特别是剖析其内存架构与数据处理本质时,会发现许多所谓的“超节点”产品,不过是旧有“服务器堆叠”模式披上了一层新的外衣,其核心短板——缺乏真正的内存统一编址——使其难以兑现革命性的承诺。
让我们澄清两个核心概念:内存统一编址与服务器堆叠。
真正的内存统一编址(如UMA, Uniform Memory Access, 或在更大尺度上追求的“内存池化”或“内存分解”),旨在将集群中多个物理服务器的内存抽象为一个巨大的、连续的共享地址空间。应用程序可以直接、透明地访问远超单机容量的内存,无需复杂的数据迁移和拷贝,这能极大简化编程模型,并显著提升数据密集型应用(如大规模图计算、实时分析、内存数据库)的性能。这是迈向“一台计算机”愿景的关键一步。
而服务器堆叠,本质上是通过高速网络(如InfiniBand, RoCE)将多台独立的服务器连接起来,每台服务器仍保有自己独立的内存空间和操作系统。虽然可以通过软件(如分布式共享内存系统、远程直接内存访问RDMA)实现跨节点的内存访问,但这并非“统一编址”。数据访问存在明显的远近之分(NUMA, Non-Uniform Memory Access扩展到集群级别),编程复杂,性能受网络延迟和带宽制约严重,本质上仍是分布式系统。
许多标榜为“超节点”的解决方案,其技术实质正是后者。它们可能将计算、存储硬件封装在一个机箱内,通过内部高速互联(如PCIe Switch)提升了带宽,降低了延迟,比传统的通过网络交换机连接的服务器集群更紧密。在内存架构上,并未实现根本性突破:
- 独立内存空间:每个处理器或计算模块仍然直接管理其本地内存。跨节点内存访问需要通过特定的API(如基于RDMA)显式进行,对应用不透明。
- 软件栈复杂:为了模拟“统一”的体验,需要复杂的中间件、驱动和虚拟机监控器(Hypervisor)来管理数据分布和访问。这本身引入了开销和复杂性。
- 扩展性局限:随着节点增加,跨节点访问的比例和延迟问题会线性或非线性增长,无法像真正统一内存系统那样近乎线性扩展。
这种架构直接影响了其“数据处理和存储支持服务”的能力:
- 数据处理瓶颈:对于需要频繁随机访问大规模数据集的应用,跨节点内存访问的网络延迟(即使是微秒级)将成为关键瓶颈。数据处理引擎(如Spark、Flink)仍需精心设计数据分区和本地性策略,无法像使用单机大内存那样自由。
- 存储服务的本质:许多“超节点”强调其超融合特性,将存储服务(如分布式存储软件)直接运行在每个计算节点上。这确实是服务器堆叠架构的典型应用——通过软件定义存储将各节点的本地磁盘聚合为统一存储池。但这与内存统一编址是两个不同层面的问题。其存储性能的提升主要得益于更紧密的硬件集成和更快的内部互联,而非内存架构的革命。
- 支持服务的效率:运行在之上的数据库、缓存等中间件服务,若要实现极致性能,仍需感知底层节点拓扑,进行数据分片和副本放置优化,无法完全摆脱分布式系统的管理复杂度。
因此,当下许多“超节点”产品,可以视作是“高度集成化的、优化了内部互联的服务器堆叠集群”。它比传统分散式集群有优势,但并未跨越到内存统一编址所代表的新范式。
真正的技术前沿正在朝打破“服务器”边界、实现资源池化的方向努力,例如通过CXL(Compute Express Link)互联协议构建真正共享的内存池,或通过新型硬件和操作系统支持实现内存的“分解”与按需分配。这些技术有望在未来重新定义“节点”的概念。
结论是,在评估“超节点”或任何集成化系统时,需穿透营销术语,直击其内存架构本质:是实现了透明的、统一编址的共享内存,还是仅仅提供了更快捷的远程内存访问通道? 对于后者,我们应理性视其为服务器堆叠技术的有益演进,它能解决许多特定场景下的性能与部署难题,但不应期待其带来根本性的编程模型和适用性变革。在数据处理和存储支持服务层面,它提供了更优的集成平台,但并未消除分布式系统固有的挑战。拆开其“伪装”,有助于我们做出更贴合实际需求的技术选型与架构规划。
如若转载,请注明出处:http://www.hlkaldksa.com/product/21.html
更新时间:2026-06-19 21:31:50