浅谈大数据之HDFS 数据处理与存储支持的基石
在大数据技术生态系统中,Hadoop分布式文件系统(HDFS)扮演着数据处理与存储支持服务的核心角色。作为Hadoop项目的基石,HDFS以其高容错性、高吞吐量和处理海量数据的卓越能力,为现代大数据应用提供了坚实可靠的基础。
HDFS的设计哲学源于对“一次写入,多次读取”数据处理模式的深度优化。它将大规模数据集分割成多个数据块,并分布式地存储在由普通商用硬件组成的集群中。这种设计不仅降低了存储成本,还通过数据冗余机制确保了数据的高可用性——每个数据块默认会被复制到三个不同的节点上,即使某个节点发生故障,数据依然可以从其他副本中恢复,从而实现了出色的容错能力。
在数据处理支持方面,HDFS采用“移动计算而非移动数据”的创新理念。传统的集中式存储系统在处理大数据时,需要将海量数据通过网络传输到计算节点,这往往成为性能瓶颈。而HDFS允许计算任务被直接调度到存储数据的节点上执行,极大减少了数据移动带来的网络开销,显著提升了数据处理效率。这种数据本地化特性使得HDFS特别适合批处理作业,如MapReduce计算框架,能够在数据存储的位置直接进行并行计算。
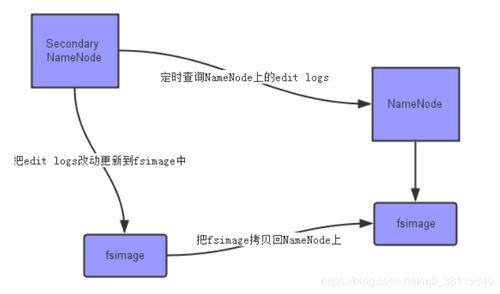
HDFS的存储架构采用主从(Master/Slave)模式,由NameNode和DataNode两种关键组件构成。NameNode作为主节点,负责管理文件系统的命名空间、访问控制及数据块到DataNode的映射关系;而多个DataNode作为从节点,实际存储数据块并处理客户端的读写请求。这种清晰的职责分离使得系统既保持了强大的元数据管理能力,又实现了存储容量的线性扩展——只需增加DataNode节点,就能轻松扩大存储规模。
随着大数据技术的发展,HDFS也在持续演进。从早期的主要支持流式数据访问,到如今逐渐增强了对随机访问、小文件存储和实时数据处理的支持。通过引入缓存机制、纠删码技术(Erasure Coding)以及与其他存储系统(如对象存储)的集成,HDFS正在不断拓展其应用边界,更好地适应云原生环境和多样化的工作负载需求。
HDFS作为大数据处理与存储的基础服务,通过其独特的分布式架构和设计理念,成功解决了海量数据存储、高并发访问和数据可靠性等关键挑战。尽管面临新型存储系统的竞争,HDFS在大数据领域的基础地位依然稳固,并继续为各类数据分析、机器学习和大规模数据处理应用提供强有力的底层支持。理解HDFS的工作原理和特性,对于构建高效、可靠的大数据平台至关重要。
如若转载,请注明出处:http://www.hlkaldksa.com/product/4.html
更新时间:2026-06-19 01:04:00