TFRecords 高效的数据存储格式与训练数据处理支持服务
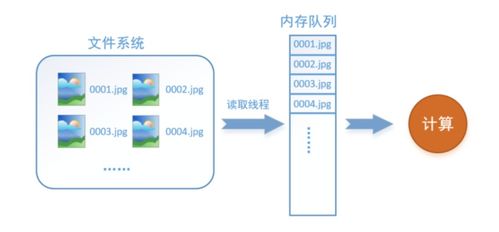
在现代机器学习和深度学习领域,尤其是在处理大规模数据集时,高效的数据存储、读取和处理流程对模型训练的性能至关重要。TensorFlow生态系统中的TFRecords文件格式,正是为解决这一挑战而设计的关键技术之一,它与配套的数据处理和存储支持服务共同构成了一个强大的数据处理流水线。
一、TFRecords:TensorFlow的高效数据存储格式
TFRecords是一种基于Google Protocol Buffers(protobuf)的二进制文件格式,专为TensorFlow设计,用于序列化存储数据样本。其主要优势在于:
- 高性能与高效存储:二进制格式比纯文本(如CSV、JSON)更紧凑,能显著减少磁盘占用,并加快I/O读取速度,这对于需要频繁从磁盘加载数据的训练过程尤为重要。
- 序列化存储:它将每个数据样本(如图像及其标签、文本序列等)序列化为
tf.train.Example或tf.train.SequenceExample协议缓冲区消息,然后顺序存储。这种结构便于TensorFlow高效地顺序读取,并天然支持并行化数据加载。 - 与TensorFlow原生集成:TFRecords与
tf.dataAPI无缝协作。tf.data.TFRecordDataset能够轻松创建输入流水线,支持并行读取、预取、混洗和批处理,最大化GPU/TPU的利用率,避免I/O成为训练瓶颈。 - 支持复杂数据结构:
tf.train.Example可以灵活存储多种类型的数据(字节串、浮点数列表、整数列表等),非常适合存储非结构化数据(如图像、音频)与结构化特征(如数值、分类标签)的组合。
创建TFRecords文件通常涉及一个预处理步骤:将所有原始数据(如JPEG图像)转换、归一化,并与标签一起封装成Example对象,然后写入一个或多个TFRecord文件。
二、数据处理与存储支持服务的完整生态
仅靠TFRecords格式本身是不够的,一个健壮的机器学习项目需要一套完整的数据处理与存储支持服务。这套服务通常涵盖以下层面:
- 数据存储与版本管理服务:
- 对象存储:TFRecords文件通常存储在高可用、可扩展的对象存储服务中,如AWS S3、Google Cloud Storage (GCS)、阿里云OSS等。这些服务提供高吞吐量和持久性。
- 数据集版本控制:使用类似DVC(Data Version Control)、Pachyderm或LakeFS等工具对数据集(包括TFRecords文件)进行版本管理,确保实验的可复现性,能够追踪每次训练所使用的具体数据快照。
- 数据预处理与生成服务:
- ETL流水线:构建自动化的数据提取(Extract)、转换(Transform)、加载(Load)流水线。该流水线负责从原始数据源读取数据,进行清洗、增强(如图像翻转、裁剪)、特征工程,并最终生成TFRecords文件。可以使用Apache Beam、TFX(TensorFlow Extended)的ExampleGen组件或Airflow等编排工具来实现。
- 数据增强:在生成TFRecords时或通过
tf.data流水线进行实时数据增强,以增加数据多样性,提升模型泛化能力。
- 高性能数据读取与传输服务(
tf.dataAPI):
- 这是连接TFRecords存储与训练计算的核心服务。
tf.dataAPI允许开发者构建复杂的输入流水线,关键操作包括:
interleave:并行从多个TFRecords文件读取数据。
shuffle:在内存或文件级别对数据进行随机化,打破样本顺序。
prefetch:在模型训练当前批次时,异步预取下一批次数据,实现计算与I/O的重叠。
map:应用预处理函数(如解码图像、归一化)。
- 分布式读取:在分布式训练环境中,
tf.data服务可以协调多个worker节点从共享存储中高效地读取不同的数据分片。
- 数据验证与质量监控服务:
- 在生成TFRecords前后,使用TFX的TensorFlow Data Validation (TFDV)等库分析数据统计信息(如特征分布、缺失值),生成数据模式(Schema),并持续监控训练数据与服务数据之间的偏斜,确保数据质量。
三、典型工作流程
一个集成了上述服务的典型工作流程如下:
- 原始数据收集:将原始数据(图片、文本等)上传至云存储。
- 预处理与TFRecords生成:触发数据处理流水线,进行清洗、增强,并批量写入TFRecords文件,存储于对象存储中。同时进行数据验证,生成Schema。
- 版本标记:使用数据版本控制工具对生成的TFRecords文件集打上版本标签。
- 训练流水线:训练任务启动时,根据指定的数据版本,从存储中读取TFRecords文件路径。通过
tf.dataAPI构建高效的数据输入流水线(包含并行读取、混洗、批处理、预取),将数据源源不断地供给训练循环。 - 迭代与更新:当需要更新数据集或进行A/B测试时,重复上述过程,生成新版本的数据集,并启动新的训练任务。
结论
TFRecords作为TensorFlow生态中高效的序列化数据格式,是优化训练数据I/O的基石。要充分发挥其效能,必须将其嵌入一个完整的数据处理与存储支持服务体系之中。这个体系涵盖了从数据存储、版本管理、预处理流水线到高性能读取和数据质量监控的方方面面。通过整合这些服务,团队能够构建出可扩展、可复现且高性能的机器学习数据流水线,从而将更多精力聚焦于模型设计与算法创新,而非数据处理的复杂性上。
如若转载,请注明出处:http://www.hlkaldksa.com/product/12.html
更新时间:2026-06-19 21:16:22