分布式数据库在数据处理与存储支持服务中的应用 海量数据存储与实时查询的实现
在当今数据爆炸的时代,传统的数据存储和查询架构面临着前所未有的挑战。随着企业数据量的指数级增长,如何高效地存储海量数据并实现毫秒级的实时查询,已成为支撑业务决策与用户体验的关键。分布式数据库应运而生,它通过将数据分散存储在多台独立的服务器上,构建了一个高度可扩展、高可用且高性能的数据处理与存储支持服务体系。
一、 分布式数据库的核心优势:构建弹性数据基石
分布式数据库的核心思想是“分而治之”。它将一个庞大的数据集分割成多个较小的片段(分片),并将这些分片分布到网络中的多个物理节点上进行存储和处理。这种架构带来了多重核心优势:
- 海量存储与线性扩展:存储容量和处理能力可以通过简单地增加节点来近乎线性地提升,轻松应对从TB到PB级别的数据增长,满足长期数据存储与积累的需求。
- 高可用与容错性:数据通常会在多个节点上保存副本。当某个节点发生故障时,系统可以自动将请求路由到存有数据副本的其他健康节点,确保服务不中断,为关键业务提供7x24小时的数据支持服务。
- 高性能并行处理:查询和计算任务可以被分解,并在多个节点上并行执行,极大缩短了响应时间,为实现复杂分析查询和实时数据检索提供了可能。
二、 实现海量数据存储的关键技术
要实现稳定可靠的海量数据存储,分布式数据库依赖一系列关键技术:
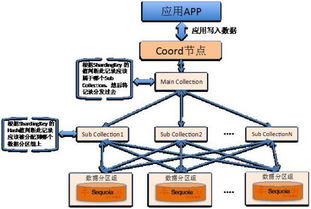
- 数据分片策略:这是分布式存储的基石。常见的策略包括基于哈希值、数据范围或列表的分片方式。合理的分片策略能确保数据均匀分布,避免“热点”节点,并支持高效的数据路由。
- 多副本与一致性协议:为保证数据可靠性,同一份数据会在多个节点(通常为3个副本)存储。这引入了数据一致性问题。系统通过Raft、Paxos等分布式一致性协议,确保在发生写入或副本同步时,所有副本最终保持一致状态,在可用性与一致性之间取得最佳平衡。
- 分布式事务管理:跨多个分片的数据更新操作需要分布式事务来保证ACID特性(原子性、一致性、隔离性、持久性)。两阶段提交(2PC)等协议被广泛应用,新型数据库也通过优化锁机制和采用多版本并发控制(MVCC)来提升事务处理效率。
三、 支撑实时查询的架构与优化
实时查询要求系统在极短时间内返回精确或聚合结果,这对分布式架构的查询引擎提出了极高要求。
- 分布式查询引擎:作为系统的“大脑”,它接收用户查询请求,生成最优的分布式执行计划。该计划将查询拆解为一系列能在各个数据节点上并行执行的子任务,最后汇总中间结果并返回给用户。
- 全局索引与二级索引:为加速查询,除了本地索引,分布式数据库还支持构建跨节点的全局索引。查询可以首先通过索引快速定位到数据所在的分片,而非扫描所有节点,这是实现低延迟查询的关键。
- 内存计算与缓存层:将热点数据或中间结果缓存在内存中,可以极大减少磁盘I/O。许多分布式数据库集成了内存计算引擎,并利用Redis等外部缓存作为补充,为实时性要求最高的场景提供亚秒级响应。
- 近实时数据摄入:为了支持对最新数据的查询,系统需要高效的数据摄入管道。通过Change Data Capture(CDC)技术实时捕获源库变更,或对接Kafka等消息队列实现流式数据接入,确保数据能在秒级甚至毫秒级内可供查询。
四、 在数据处理与存储支持服务中的典型应用
凭借上述能力,分布式数据库已成为现代数据处理与存储支持服务的核心引擎,广泛应用于:
- 互联网与数字业务:支撑电商平台的交易订单、用户行为日志存储与实时商品推荐;支持社交媒体的海量用户动态、消息流与即时搜索。
- 金融科技与风险管理:用于存储全量交易流水,实现实时反欺诈检测、信用风险实时评估和合规监控。
- 物联网与智能制造:存储来自海量传感器和设备的时间序列数据,并实时监控设备状态、预测性维护与分析生产效能。
- 企业级数据中台:作为统一的数据湖或数据仓库的底层存储,整合多业务线数据,为BI分析、实时报表和用户画像提供高并发查询服务。
分布式数据库通过其创新的架构,成功地将海量数据存储的“容量难题”与实时查询的“速度挑战”转化为可管理、可扩展的技术方案。它不仅仅是存储工具的升级,更是构建敏捷、智能的数据处理与存储支持服务的战略性基石。随着云计算、人工智能的深度融合,分布式数据库将继续演进,以更强的弹性、更智能的自治管理和更丰富的实时分析能力,驱动各行各业的数字化转型与数据价值释放。
如若转载,请注明出处:http://www.hlkaldksa.com/product/18.html
更新时间:2026-06-19 12:41:22